zj
后端:
算法一个先递增再递减的数组,给一个数找到它的位置索引
给你一段文本,怎么建立一套索引
这几年做的最有成绩的一项工作或者一个点
说说你这几年的成长
说说你的自我学习的方式
你说自学了点机器学习的,学的怎么样
前端:
Python的一个名字里带io的插件,python异步编程
nodejs做过些什么东西,对nodejs做服务端和Java的差异说一下
nodejs的io说下
带过团队吗
做没做过端到端测试
对于线性代数的掌握?
列举对于性能优化的几种使用
说下web(客户端和服务器端)的缓存机制
http和https的不同
一个请求从发出到结束的全过程
一段文本,怎么建立一套索引(倒排索引)
https://blog.csdn.net/njpjsoftdev/article/details/54015485
https://segmentfault.com/a/1190000014480912
http://www.nosqlnotes.com/technotes/searchengine/lucene-invertedindex/
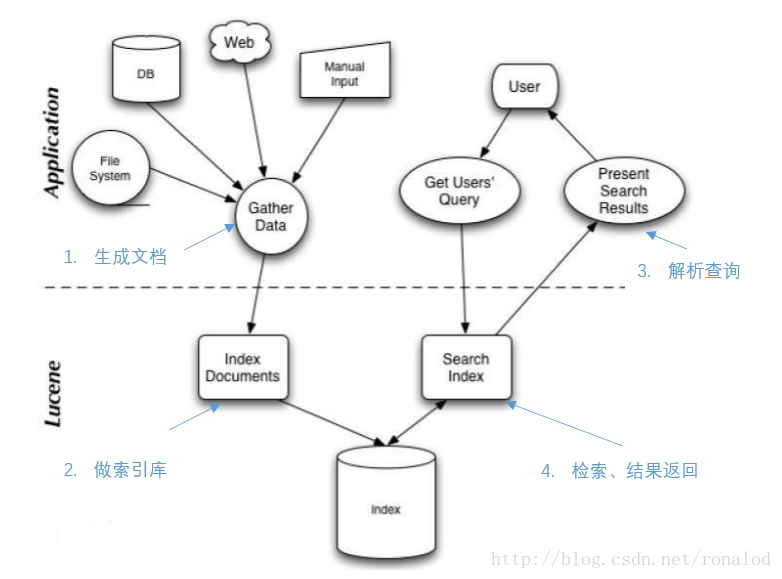
倒排索引示例
文章1的内容为:Tom lives in Guangzhou,I live in Guangzhou too.
文章2的内容为:He once lived in Shanghai.
分词后
文章1的所有关键词为:[tom] [live] [guangzhou] [i] [live] [guangzhou]
文章2的所有关键词为:[he] [live] [shanghai]
建立倒排索引
关键词 文章号
guangzhou 1
he 2
i 1
live 1,2
shanghai 2
tom 1
加上“出现频率”和“出现位置”信息后,我们的索引结构变为:
词典文件(Term Dictionary): 关键词
频率文件(frequencies): 文章号[出现频率]
位置文件 (positions): 出现位置
关键词 文章号[出现频率] 出现位置
guangzhou 1[2] 3,6
he 2[1] 1
i 1[1] 4
live 1[2] 2,5,
2[1] 2
shanghai 2[1] 3
tom 1[1] 1
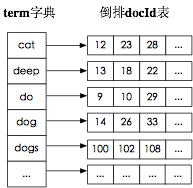
FST : 存储词典信息(即:关键字)
词典文件: 使用 FST(Finite State Transducers: 有限状态机) :这是一个有向无环图
示例
插入“cat”

插入“deep”

插入“do”

插入“dog”

插入“dogs”

使用SkipList存储Docid:主要解决“与(合并)”的问题
DocID: SkipList(使用跳表而不是B+Tree: 因为BTree占用空间太高)
使用SkipList存储DocId列表的原因: 很适合求交集
有序链表集合求交集,跳表是最常用的数据结构,它可以将有序集合求交集的复杂度由O(n)降至O(log(n))
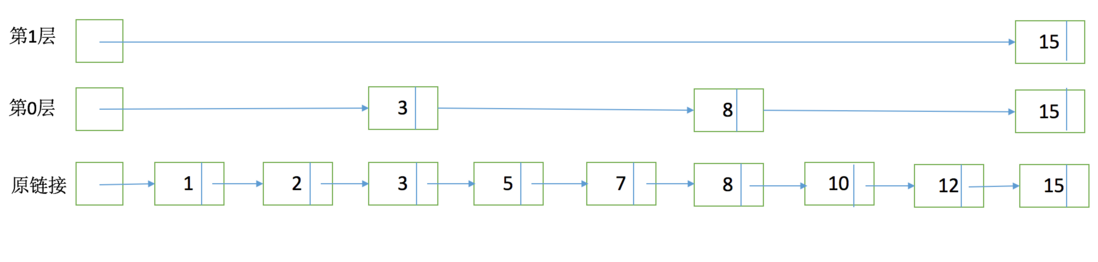
FST + SkipList 存储字典信息和DocId信息
FST和SkipList
性能优化
代码优化
- 多线程;
- 过多次的Http调用;
- 重复逻辑、for循环过多;
数据库优化
sql调优
架构层面的调优
- 分库分表(垂直拆分,水平拆分)
- 读写分离
- 多从库负载均衡
连接池调优
各种调优参数
缓存
异步
NoSQL
如使用MongoDB、ELK等
JVM调优
多线程与分布式
Http和Https的区别
https://segmentfault.com/a/1190000011185129
HTTP+加密+认证+完整性保护 = HTTPS.
认证: 确保服务器是真实可信,而不是伪装的,使用数字证书解决;
加密: 非对称加密(用于传输对称加密的密钥) + 对称加密
完整性保护:
通俗的说:
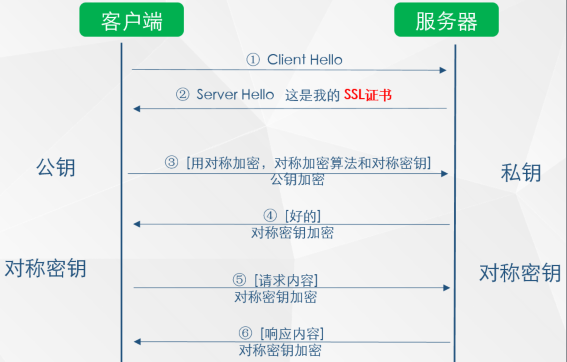
客户端 -> 服务器: 问服务器要数字证书(该数字证书会包含非对称加密的公钥)
客户端: 认证数字证书是否可信,如果可信,会将
对称加密的密钥使用公钥加密后传给服务器;服务器 <-->客户端: 使用约定的
对称加密-密钥进行数据传输;
HTTPS: HTTP + SSL/TLS 协议 (HTTP over SSL)
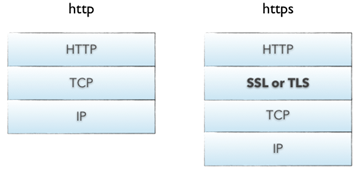
- SSL协议(Secure Sockets Layer):SSL运行在TCP/IP层之上、应用层之下
- TLS(Transport Layer Security):传输层安全协议
对称加密 vs 非对称加密
对称加密: 加解密使用相同的密钥;
非对称加密: 加密和解码使用不同的密钥;
HTTP 和 TCP 之间的关系
HTTP 协议需要依靠 TCP 协议来传输数据
HTTP对TCP的使用:
- 短连接
- 长连接(Keep-alive)
SSL/TLS协议的基本运行过程
- 采用公钥加密法
- 客户端: 先向服务器端索要公钥,然后用公钥加密信息(重点:
客户端持有公钥) - 服务器:收到密文后,用自己的私钥解密;(重点:
服务器端持有私钥)
主要解决两个难题:
1. 验证服务器的可信性;(使用数字证书);
2. 合理使用对称和非对称加密,提高性能;
解决服务器可信问题: 数字证书
如何保证公钥不被篡改:将
公钥放在数字证书中,只要数字证书可信,公钥就可信;
解决性能问题:
非对称加密性能低,对称加密性能高,如何保证性能?
解决方式:
- 非对称加密: 只用于传输对称加密的密钥;
- 对称加密: 用于传输具体的数据;
具体过程:
1. 客户端向服务器端索要并验证公钥;
2. 双方协商生成“对话密钥”(这个密钥用于对称加密);
3. 双方采用“对话密钥”进行加密通信(对称加密)。
区别总结
-
https协议需要到ca申请证书,一般免费证书很少,需要交费。
-
http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3.http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4.http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全
web服务器的缓存机制(client和server)

反向代理后后端
请求:浏览器 -------> Nginx反向代理 ------------> web服务器 --------->DB
返回:浏览器 <------- Nginx反向代理 <---------- web服务器 <--------- DB
缓存:客户端缓存 HTTP服务器缓存 数据库缓存
(浏览器缓存) 应用缓存
应用页面缓存
服务端缓存
- 页面缓存
- 数据缓存: 内存缓存 + 文件缓存
- 数据库缓存: 数据库自己提供(TODO: 如何设置mysql读取缓存)
客户端缓存
- 浏览器缓存
- 代理服务器缓存
- 网关缓存(
反向代理缓存)
应用层数据缓存
缓存数据库的查询结果
实际示例: 日志审计,查询时间范围长(需要跨多库跨多表,甚至跨节点)的日志个数,将查询结果保存在文件中,每次先读取文件内容,在考虑是否查数据库;
预先加载数据:可以在系统启动时预加载
比如: 获取部门、业务系统等维度的主机列表信息
写入缓存: 对一直性要求不高的数据,可以先将数据写入到内存中,然后慢慢写回数据库
比如:文章访问个数;
比如:操作日志,先写入redis,在写入数据库;
HTML片段缓存
浏览器缓存
服务器通过设置响应的HTTP头,来通知浏览器按照服务器的要求进行响应的缓存。(重点:服务端设置缓存参数,浏览器对缓存参数进行响应)
常用参数:
- Expires: 过期缓存。这种缓存是最快的,因为没有任何HTTP请求的发生。当用户需要这个资源的时候,浏览器就直接从缓存(在硬盘中)读取,不再需要询问服务器端的意见。
- Last-Modified: 最后修改时间。通过这种缓存方式,无论资源是否发生了更新,仍然至少会发生一来一去HTTPS头的传输和接收,所以速度比不上Expires。
- ETag: 实体标签。和Last-Modified类似,也是WEB服务器和客户端用于确认缓存组件的有效性的一种机制。当资源被修改,其ETag也发生改变。ETag相对Last- Modified更精确,但在多服务器可能造成混乱。
- Cache-Control: 缓存控制。这个字段用于指定所有缓存机制在整个请求/响应链中必须服从的指令。这些指令指定用于阻止缓存对请求或响应造成不利干扰的行为。比如:Cache-Control: max-age=3600, public
TODO:
Spring MVC如何设置浏览器缓存参数?